This post is part two in a three part series on the challenges of improving a production machine learning system. Find part one here and part three here.
Adding New Features or Improving Existing Features
A machine learning model is only as powerful as the features it is trained with. As a result, one of the most important parts of improving a machine learning system is improving the core feature set. However, experimenting with new features or feature improvements presents a unique set of challenges.
Online Version vs Offline Version
Probably the most straightforward challenge of adding new features is offline/online mismatch. This problem arises when the processes by which features are derived from raw data are different between the systems for model training and model serving.
This problem is particularly common when a model is trained and deployed in different environments. For example, suppose we train a model in a notebook on a cloud machine but deploy it to run in a user’s browser. The feature computation code in these two settings may be written in different languages, and slight differences in serialization, tokenization, rounding, etc are very common.
Even in the situation that the feature serving code is identical between the training and inference pipelines, it is common for the data itself to be different. For example, it is often most cost efficient for organizations to use low-latency key-value stores like redis or bigtable to serve features online but to use data warehousing solutions like hadoop or bigquery to manage features for offline model training. It is possible for substantial differences to exist between how data is written, stored, and accessed between these different tools.
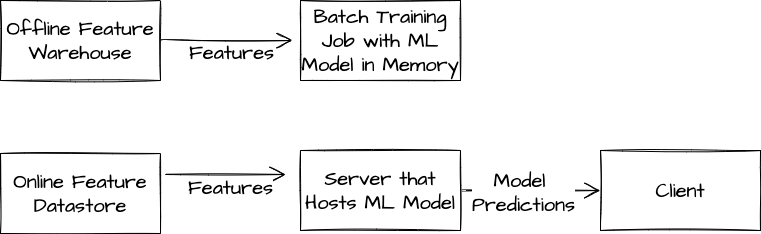
Finally, even when the features themselves are identical, the systems for providing features at inference time may fail or timeout. This is particularly common in large distributed systems with tight latency constraints. Even if the ML system is engineered to handle these failures gracefully, these events can cause differences between the feature distributions at training and inference time.
Time Travel
Another well known challenge with feature experimentation is time travel. Time travel arises when we use a feature that is computed at time t2 to train or evaluate a model on a sample that was derived at some time t1 != t2. This can skew the feature distribution and lead to mismatch between the training and inference feature distributions. This is particularly risky when t1 < t2, since it is possible for the label to “leak” into the feature distribution.
For example, suppose we are training a click prediction model, and one of the features in the model is the number of clicks that the user has performed in the last 30 days. Now suppose we use the value of this feature at time t2 to predict the probability of a click at t1 where t1 < t2. The model will likely overindex on the importance of this feature, since the user’s decision to click at time t1 is already included in the value of the feature at time t2.
Time travel is easy to avoid when the set of features that we use is constant. We can simply log the feature set at prediction time, and then use the logged features for training and evaluation. However, we cannot use this strategy when we add a new feature or want to experiment with a new strategy for computing a feature. In these situations the only recourse may be to start logging the new features for a while before using them to train a model.
Feature Freshness
In most machine learning applications we can divide features into two categories:
- Static features that change slowly and don’t need to be updated often. This includes things like user age, text content, and media content.
- Dynamic features that change quickly and rely on regular updates. This includes things like a user’s last action, today’s weather, or a sensor’s last health report.
If a model is trained to expect that dynamic features are computed with a 2-hour lag, then either system outages that increase that lag or performance improvements that reduce that lag can damage model performance.
To Be Continued
That’s all for now. In our next post we will explore some of the challenges of A/B testing improvements to a machine learning system.