Suppose you are a payment processor handling thousands or millions of payments every day. Some small number of the payments that you process are bound to be fraudulent. How can you spot them?
This problem - identify a small number of bad events in a sea of good events - is known as detection. This shows up in many domains: fraudulent payments, phishing emails, illegal social media posts, etc.
Detection is a subcategory of classification, so one approach to solve a detection problem is to extract a bunch of features from events and throw a ML model trained on “bad” vs “good” at the problem. This is tough in practice. Interpretability tends to be paramount (people want to know why their payment was bounced), labels can be expensive to acquire and balance (especially since good events can be extremely diverse and many orders of magnitude more common than bad events), and the core problem is adversarial (malicious actors change up their techniques whenever they stop working).
For these reasons most organizations operating a detection engine use rules as a detection baseline. An example payment fraud detection rule might be:
(
address_verification_fails = true
AND previous_fraud_count > 0
) OR (
cvc_verification_fails = true
)
Organizations generally express these kinds of rules through a rule engine like Stripe Radar. These kinds of rules have a lower performance ceiling than an end-to-end ML model, but their interpretability and editability make them useful baselines.
There is a simple human-in-the-loop algorithm that analysts can follow to write good detection rules.
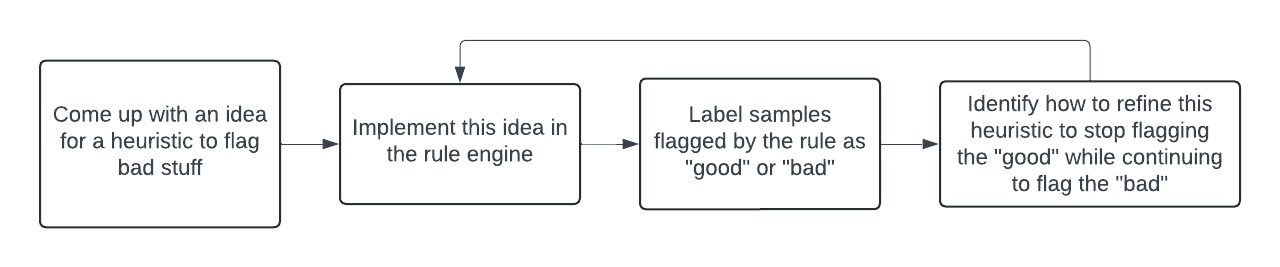
This human-in-the-loop algorithm doesn’t look too different from an ML model training algorithm - the rule evolves in an iterative fashion as human provided labels identify incorrect judgements. This raises the question - can we automate this process by replacing the human-in-the-loop components with an LLM?
Breaking this down, we need to replace human judgements with LLM judgements in two tasks:
- Task 1: Given a sample that the rule flagged, label it as “good” or “bad”
- Task 2: Given documentation for the rule engine, a rule, a set of good samples flagged by that rule and a set of bad samples flagged by that rule, modify the rule so that all bad samples remain detected and as many good samples as possible are filtered out.
One simple way to solve Task 1 is to use a prompt like the following:
You are a fraud detection agent reviewing payments for evidence of fraud.
Here are detailed instructions on how you spot fraud in a payment:
…
Here are some examples of previous fraudulent payments:
…
Here are some examples of previous legitimate payments:
…
Please inspect the following payment:
…
Is this payment fraudulent?
The performance of this prompt will likely by bottlenecked by how well the payment is described to the model. Any information about the payment that a human labeler might use to judge whether the payment is bad should be included in the prompt. More complex solutions to Task 1 might involve finetuning the LLM on labeled data or breaking the problem into subproblems handled by separate agents.
We can solve Task 2 by writing a prompt like the following alongside a parser to pipe the output back into the rule engine:
You are a fraud detection agent writing a fraud detection rule.
Here is the set of all signals that are available in your rule writing engine:
…
Here is the syntax of your rule writing engine:
…
Here is the rule you have written so far:
…
You can edit this rule by generating an output in the following format:
…
This rule correctly flags the following fraudulent payments:
…
This rule incorrectly flags the following legitimate payments:
…
Please edit this rule to continue flagging these fraudulent payments and no longer flag these legitimate payments.
In high noise domains the resulting rule may actually have higher accuracy than the LLM labeling agent itself. Forcing the algorithm to be expressed as a simple rule (rather than the black magic voodoo going on inside of the LLM) enables Occam’s Razor to work its magic.
This approach can substantially cut down on the human effort required to operate a rule-based detection engine without sacrificing the simplicity, interpretability and editability of the detection logic.